Deeplake Blog
Software Factory Ran Autonomously for 15h, 2x Speed Up on TPC-H, ASAN-verified, Cost $160
An autonomous agentic workflow achieved a 2x speedup on TPC-H benchmarks by optimizing a large C++ codebase over 15 hours for just $160.
Table of contents
I have finally achieved the dream of every founder: an employee that works for fifteen hours straight, never asks for a promotion, and only costs $160 in electricity and reasoning.
What if I leave it for 15 hours? Would it damage my storage engine?
Running agents autonomously for long term tasks without intervention is a challenge. They easily generate 10K+ lines of AI slop, diverge or contaminate the context. LLMs can’t reliably interact with large existing codebase without human supervision. Autonomously building a mission critical software, such as a database software, is unrealistic. However, we made it possible with sophisticated harness.
We let it run for 15 hours autonomously. Output was 83 lines of highly optimized C++ code. 714 lines of tests. 8:1 test to code ratio. It fixed the bottleneck in a large codebase. Improved the TPC-H benchmark 2x. Verified memory leak using ASAN. Spent $160 of LLM calls.
This only worked because of the setup. The harness surrounding agents is the bottleneck. Let’s deep dive on details.
How is Deep Lake built?
At Activeloop, we built Deep Lake, a data lake for AI memory retrieval and training. We have the following codebases
deeplake- data lake for AI memory retrieval and trainingpg_deeplakepostgres extension- our proprietary core engine
This spans over 250,000+ lines of human-crafted C++ code developed over the past few years. Here is a simple diagram.
+----------+ +-------------+ +--------------------+ +--------+
| Postgres | ---> | pg_deeplake | ---> | DuckDB + Deep Lake | ---> | S3 |
+----------+ +-------------+ +--------------------+ +--------+Our codebase has three components that need to get compiled: Postgres extension, DuckDB and Deep Lake core. While Postgres became standard for database interface and DuckDB the query engine, storage engine is a missing piece. Deep Lake aims to fulfill it.
End to end building the code without cache takes 30 mins. By itself, this would be a bottleneck for agentic iterations. We reduced it under 1 minute with incremental compilation via ccache. Similarly, we run only essential tests. Large ones would run prior to merging final PR. To iterate fast on benchmarks, we use ‘mini’ version of TPC-H during runtime. Total sandboxed execution takes up to 3 minutes.
Most of my time was spent on building the infrastructure harness around the agent rather than iterating on prompts. It is vital to have fast incremental builds, staged dockers, fast runnable tests and benchmarks against running multi-container setup. All the boring work that should have been done years ago is the bottleneck to unlock autonomous software development. Ironically you will see later that having just one more tool ready to go would have made the total cost 3x less.
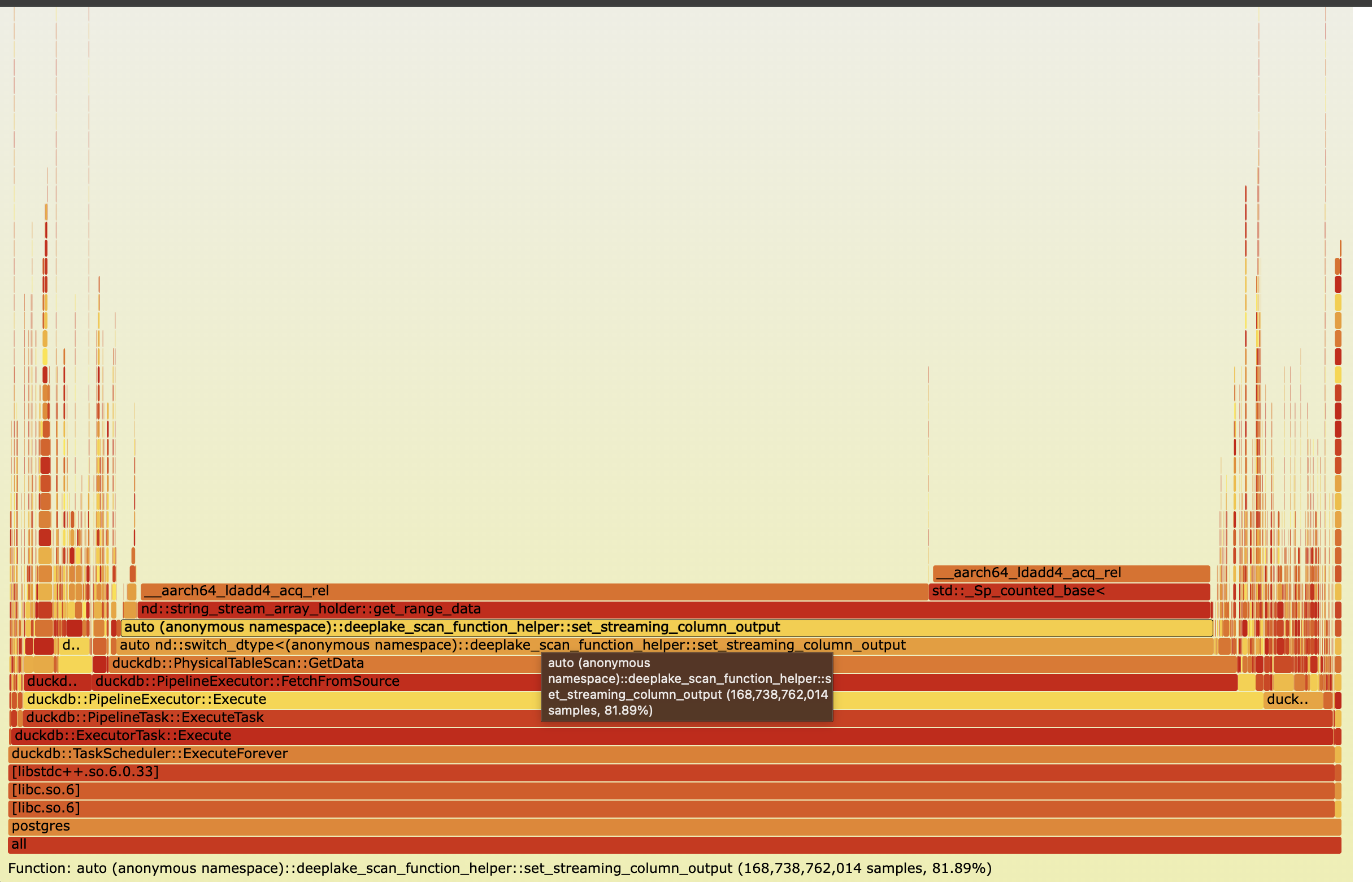
First let’s run the benchmark and collect performance logs. In the flamegraph below, we could notice that middle slit takes 82% of total time average during execution of queries. That function reads string data from deeplake format.
Spec-Driven Development
Having a clear plan is as important as successfully executing it. I was recently talking to a founder building enterprise agents. They spend 50% of LLM calls on planning the perfect spec before agents execute it for 2 days. Cursor’s blogpost also signifies the importance of the planner. To index the codebase, I initially used recursive language models. It had REPL with full code access to recursively call itself until plan is generated. However, I found out that Claude Code treated as an LLM does much better job at ‘indexing’ the codebase and generating a plan.
More importantly it produces highly precise spec. Once the draft plan is provided by Claude, then we loop over LLMs critics to modify it until all critics accept. Here we use mix of models to reach consensus such as Opus 4.5, GPT 5.2 Codex, Gemini 3 Pro.
> activeloop --plan "Given insights in ~/run_0d032e3e come up with plan \
that reduces TPCH execution time 2x. potentially look into memory access \
patterns for strings that require dereferencing, string copies into duckdb \
internal buffer." --iterations 10 --maxHere is the plan it generates.
TLDR: Profiling showed string extraction dominated by atomic reference counting in a tight loop. We planned a zero-copy path that caches backing pointers during batch initialization to avoid refcount churn. Added unit tests + ASAN validation. This removed the hotspot in perf and improved end-to-end query time, though total speedup is bounded by downstream engine overhead.
Critic iterations helped to refine risks, come up with mitigations and how to verify if a step has been successfully completed. Generating the plan cost about $10 with 10 critic iterations.
Cycling
Worker takes the plan and starts executing in cycles. We treat a Claude Code as an LLM. Provide the plan with a generic prompt to execute against plan. Per cycle we run two Claude Code sessions. One executes the code, other one verifies against the plan. Each cycle took an average of 20-30 minutes. Similarly you can take Codex, OpenCode, any other scaffold or mix them together.
> activeloop run plan-243af5b1 --model opus --max-hours 24 \
--cycle-hours 4 --show-reasoning --benchmark
======================================================================
GRIND MODE - Long-running Autonomous Execution
======================================================================
Plan: plan-243af5b1
Goal: Reduces TPCH execution time 2x...
Mode: dev
Cycle hours: 4.0
Max hours: 24.0
Show reasoning: True
Require benchmarks: True
Model: opus 4.5
Verification: ALL through activeloop (compile + test + benchmark)
======================================================================
[19:05:29] → Plan loaded with 9 implementation steps
[19:05:29] → Mode: dev
[19:05:29] → Executor: claude_code
[19:05:29] → Goal: Reduces TPCH execution time 2x...
============================================================
[19:05:29] → CYCLE 1 (elapsed: 0.00h / 24.0h)
============================================================
[19:05:29] → Starting Claude Code execution
[19:05:29] · Timeout: 4.0h, Model: opus
[19:05:32] 📝 Ill start by implementing this plan. Let me first understand the current state of the code and then work through the steps.
[19:05:36] #001 Todo: Add minimal unit test for string_stream_... (9 items)
[19:05:39] #002 Read: .../cpp/nd/string_array_holder.hpp
[19:05:39] #003 Read: .../cpp/nd/string_array_holder.cpp
[19:05:40] #004 Read: ./cpp/tests/nd/array_test.cpp
[19:05:43] 📝 Now let me check the existing test file that was started, and look at the chunk_array.hpp for full_chunk_data_t to understand how to create test data.
[19:05:44] #005 Read: .../cpp/tests/nd/string_array_holder_test.cpp
[19:05:45] #006 Read: .../cpp/chunk_format/impl/chunk_array.hpp
[19:05:49] 📝 The test file already exists with tests for the dynamic string path. Now I need to add tests for the range path. Let me check the range_array.hpp to understand how to create test data for the range pa...
[19:05:49] #007 Read: ./cpp/nd/impl/range_array.hpp
[19:05:50] #008 Read: .../cpp/nd/impl/stacked_array.hpp
[19:05:55] 📝 Now I understand the structure. The test file already has tests for the dynamic path. I need to add tests for the range path which uses `full_chunk_data_t` (dynamic_full_chunk_bytes_array::dynamic_ful...
[19:05:56] #009 Grep: 'class memory_buffer' in .../cpp
[19:06:00] #010 Grep: 'memory_buffer' in ...it /cpp/base
[19:06:03] #011 Read: /cpp/base/memory_buffer.hpp
[19:06:06] #012 Read: /cpp/base/read_buffer.hpp
[19:06:10] 📝 Now I understand the structure. To create test data for the range path (using `full_chunk_data_t`), I need to:
1. Create `base::memory_buffer` with raw string data
2. Create `icm::vector<uint32_t>` of...
...Memory across Cycles
While context easily gets contaminated during long running sessions, we store all logs produced both from the agent and sandboxed execution into Deep Lake exposed as a File System. Don’t worry, Deep Lake version here is fixed across iterations. Each iteration generates over ~300MB of performance logs. After each cycle, context is cleared out, but agent has access to the memory. It unblocks long running sessions without losing context.
This section on its own deserves a separate blogpost. We will release it upcoming week including the module we built to manage the memory.
Verification
At the end of execution, verifier is being called. Each plan has custom generated verification steps defined in the plan. We supplement the agent with direct commands on compiling, running basic tests, and running the benchmark. Here is Cycle 14 output.
# after 6h of execution
----------------------------------------
[01:04:20] ✓ Cycle 14 complete: 2 files modified
[01:04:20] ✓ Compilation: PASSED
[01:04:20] ✓ Tests: PASSED
[01:04:20] ✓ Benchmarks: PASSED
[01:04:20] · Duration: 0.10h
[01:04:20] → Verification feedback will be passed to next cycle
[01:04:20] → Running judge evaluation...
[01:04:20] → Running plan step verification...
[01:04:20] ✓ Step 1: Add minimal unit test for string_stream_... (already verified)
[01:04:20] ✓ Step 2: Run profiling sanity check with UNCOMMIT... (already verified)
[01:04:20] ✓ Step 3: Verify is_valid_ fix correctness in work... (already verified)
[01:04:20] ✓ Step 4: Add clarifying comment to data_batch() e... (already verified)
[01:04:20] → Verifying Step 5: Run ASAN build to verify memory safety...
[01:05:17] ✗ Step 5: FAILED - Step 5 was not implemented - no ASAN build was created or ex
[01:05:17] ✓ Step 6: Commit existing optimizations with descr... (already verified)
[01:05:17] ✓ Step 7: Run full TPCH profiling with optimized c... (already verified)
[01:05:17] ✓ Step 8: Verify holder lifetime in pg_deeplake (c... (already verified)
[01:05:17] ✓ Step 9: Optional: Update pg_deeplake to use data... (already verified)
[01:05:17] ⚠ Verification complete: 8/9 steps verified
[01:05:17] ⚠ HARD GATE: Only 8/9 plan steps verified
[01:05:17] → Judge decision: CONTINUE - Making progress (or fixing verification failures)
[01:05:17] → Proceeding to next cycle...
============================================================
[01:05:17] → CYCLE 15 (elapsed: 6.00h / 24.0h)
============================================================
[01:05:17] → Starting Claude Code executionAfter each cycle, the verifier checks against the plan (i.e. did we run ASAN to verify memory leaks). Summary is passed to the next cycle.
Our harness setup did not have ASAN by default to verify memory leaks. To be fair our engineers used it before. Planner should have found hints in GitHub actions to add to the verification step. However, it was not directly given as a tool with easy access. Since this was a required step for completion, it spent 10h out of 15h to figure out how to run ASAN. Providing the agent necessary tooling, would cut the time further by 3x.
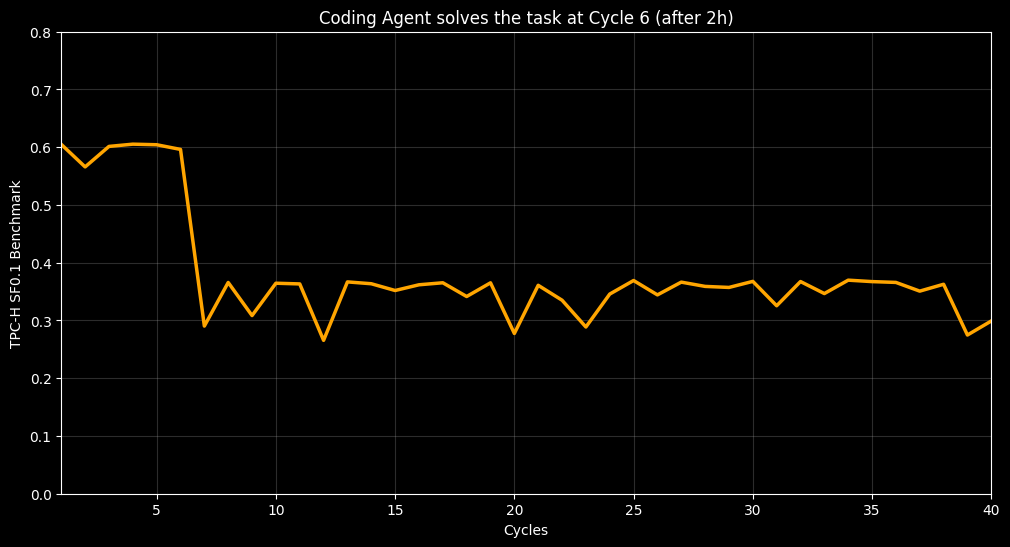
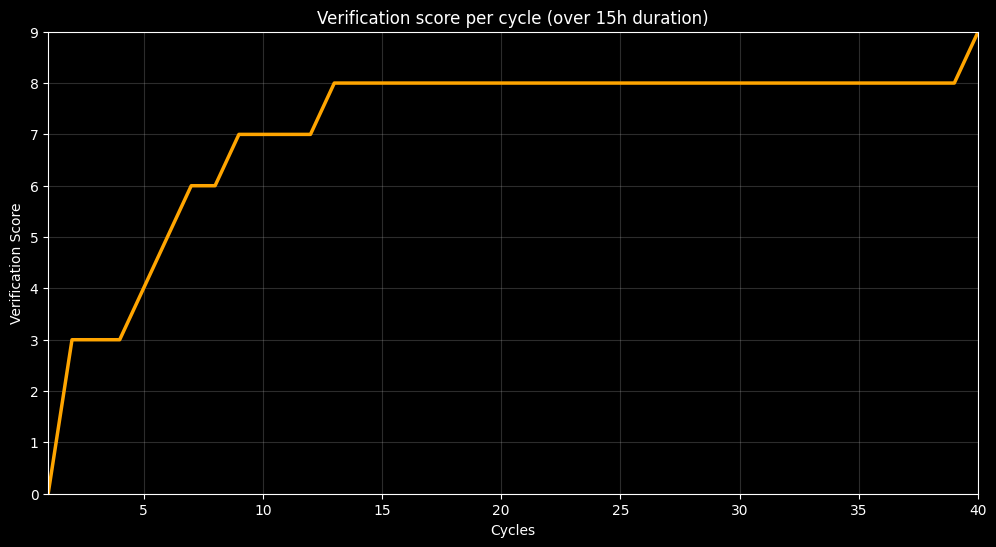
The Results: A 2x Speedup
The agent iterated over 40 cycles in 15h. Spent about ~$150 on execution itself. 83 LoC focused on removing atomic contention in the hot path. It came up with two PRs across our two codebases. 714 lines of tests with 8:1 ratio. All this, instead of 10K+ AI slop code that won’t be human readable anyway.
All tests passed on CI/CD with green checkmark. After manually reviewing the code, our CTO said it could have used encapsulation, and better follow C++ guidelines. He then manually did a refactoring touch and merged into production.
At the end we can see that Deep Lake bottleneck was removed from query execution.
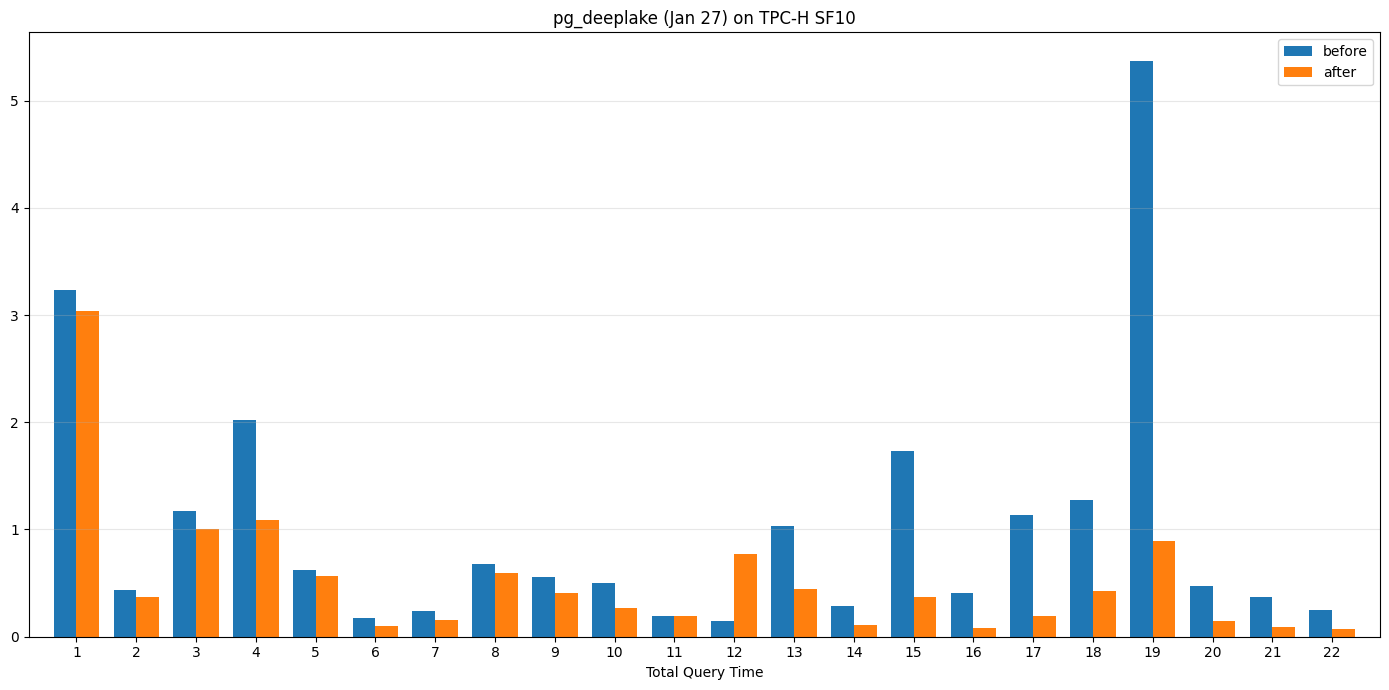
We run the full benchmarks on TPC-H SF10 scale. Observed that average query time was indeed reduced by ~2x from 1.01s → 0.52s.
The “Software Factory” Future
This can be pointed to any task, even a single query, to introduce a new feature, optimize or fix a bug.
- Coding agentic scaffolds such as Claude Code, Codex, OpenCode achieved equivalent of ‘Senior Software Engineer’ intelligence past few weeks. High-reasoning executor is only limited by infrastructure.
- Harness surrounding the agent is as important as the agent itself. Claude Code spent 70% of time on figuring out how to run ASAN and verify memory leaks. Providing all infra tooling unlocks significant time saving.
- Agent Memory is the last bastion to unlock long horizon workloads, equivalent to Continuous Learning. Deep Lake enabled us to have long term memory across long running Cycles.
Those are early signs how software engineering as a practice is undergoing a fundamental change. While I have been realist for past a year or two on AI’s impact on software engineering as a discipline, I would admit in the last few weeks tables have turned. It is obvious to me that every software producing company would evolve either building their own (software) factories, or die.